

Anmerkung:
In diesem Artikel beschreibe ich ausführlich, wie ich einen Alfred Workflow erstelle. Mein Ziel war es, nicht nur den Workflow selbst zu erstellen, sondern auch den Entwicklungsprozess zu dokumentieren. Bereits in diesem Artikel habe ich, unten im Nachtrag, eine Verbesserung vorgestellt. Nun, im März 2024, musste ich jedoch feststellen, dass weitere Anpassungen nötig sind, die ich im Artikel ‘Python-Skripte in Alfred-Workflows mit virtuellen Umgebungen nutzen’ beschreibe. Dieser Artikel ist trotzdem eine Voraussetzung, damit der Workflow nachgebaut werden kann.
Wie in meinem letzten Beitrag erwähnt, habe ich mich daran gemacht, meinen Bookmark-Workflow für Obsidian mit einem schöneren Ausgabeformat zu versehen. Da ich die wenigen Workflows, die ich bisher gebaut habe, mit bash oder zsh erstellt habe, wollte ich es mal mit Python versuchen.
Auch diesmal habe ich ChatGPT benutzt. Da ich für ein Bookmark die gleichen Informationen benötige wie für eine Linkpreview, also ein Bild und einen Textauszug der URL, von der aus das Bookmark erstellt werden soll, habe ich ChatGPT gebeten, ein Python-Skript unter Verwendung der linkpreview-library zu erstellen, das diese Informationen abfragt und als Markdown ausgibt. Das Ergebnis war der folgende Code:
import linkpreview
# Replace 'your_url_here' with the URL you want to generate a preview for
url = 'https://ileif.de'
# Fetch link preview information
preview = linkpreview.generate_preview(url)
# Generate the Markdown link preview tile
markdown_tile = f"""
[![{preview['title']}]({preview['image']})]({url})
**[{preview['title']}]({url})**
{preview['description']}
"""
print(markdown_tile)
Dieser Vorschlag stieß leider auf einen Fehler. Als Alternative bot mir ChatGPT einen anderen Code mit der Beautiful Soup Library an, anstatt eine Lösung für den Fehler zu präsentieren. So musste ich selbst Google bemühen, um die richtige Syntax für den Aufruf der entsprechenden Funktionen zu finden, die dann auch als Lösung von ChatGPT akzeptiert und entsprechend eigebaut wurde:
from linkpreview import link_preview
# Replace 'url' with the actual URL you want to generate a preview for
url = "https://ileif.de"
# Fetch link preview information
preview = link_preview(url, parser="lxml")
# Generate the Markdown link preview tile
markdown_tile = f"""
[]({url})
**[{preview.title}]({url})**
{preview.description}
"""
print(markdown_tile)
Und tatsächlich nun funktionierte das Skript. Als Ergebnis wurde folgendes ausgegeben:
[](https://ileif.de) **[dit und dat](https://ileif.de)** In diesem Blogeintrag beschreibe ich, wie ich einen Alfred Workflow (inkl. kostenpflichtigem Powerpack) erstellt habe, mit dem ich per Hotkey ein Lesezeichen auf einer dafür vorgesehenen Obsidian Notizseite hinzufüge. Wobei ich wieder mit Hilfe von ChatGPT ein Shell-Script für diesen Workflow erstellt habe. Die Vorgehensweise und auch das Script können sicherlich auch für Implementierungen ohne…
In der ersten Zeile sollte eigentlich ein Link zu einem Bild stehen, da die Homepage aber kein Bild hat, steht hier „None”. Danach folgt eine Leerzeile und der Titel der Website inkl. Link und in der nächsten Zeile ein kleiner Textauszug.
Bei einem Beitrag mit einem entsprechenden Bild sieht das Ergebnis dann so aus:
[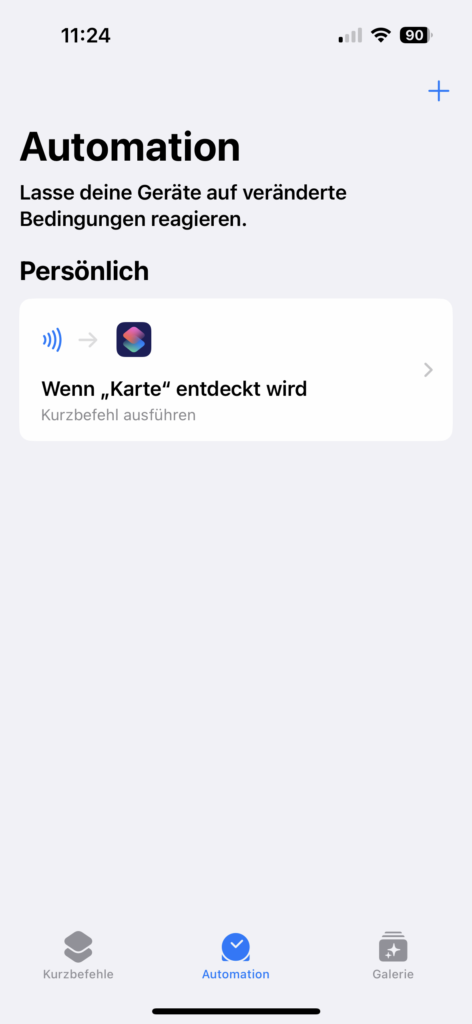](https://ileif.de/2023/08/16/nfc-tags-nutzen/)**[NFC Tags nutzen - dit und dat](https://ileif.de/2023/08/16/nfc-tags-nutzen/)** Auf iPhones können NFC-Tags relativ einfach für verschiedene Aufgaben eingesetzt werden. Dabei gibt es zwei Möglichkeiten. Zum einen der Apple-Weg, bei dem das Erkennen eines Tags eine Aktion oder einen Kurzbefehl auslöst. Der zweite Weg ist das Beschreiben des Tags mit Daten, welche die Aktion definieren, die beim Erkennen des Tags ausgelöst werden soll. was auch bei Android funktioniert.
Da ich aber immer ein Bild angezeigt haben möchte, ist noch eine Abfrage notwendig, die einen Fallback mit einem „No Image” Bild einbaut, wenn die Abfrage nach dem Bild „None” ergibt. Außerdem muss der Code so erweitert werden, dass beim Aufruf die URL als Parameter übergeben werden kann:
import sys
from linkpreview import link_preview
def generate_markdown_tile(url):
preview = link_preview(url, parser="lxml")
# Check if the image is None and replace it with a default image URL
if preview.image is None:
preview.image = "https://example.com/noimage.png"
markdown_tile = f"""
[]({url})
**[{preview.title}]({url})**
{preview.description}
"""
return markdown_tile
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python script_name.py <url>")
sys.exit(1)
url = sys.argv[1]
markdown_tile = generate_markdown_tile(url)
print(markdown_tile)
An dieser Stelle ist es wichtig zu erwähnen, dass der Variablen markdown_tile ein formatierter mehrzeiliger String zugewiesen wird, weshalb bei der Zuweisung die Syntax f""" bla bla bla """ verwendet wird.
Da ich nun mit dem Python-Skript zufrieden war, fragte ich ChatGPT nach einer identischen Lösung als zsh-Skript, was aber damit endete, dass auch dafür linkpreview zunächst als Bibliothek und dann als Programm vorgeschlagen wurde, was beides nicht zu existieren scheint. Am Ende schlug mir ChatGPT noch eine Lösung vor, bei der der Python-Code komplex innerhalb des Scripts aufgerufen wurde.
Deshalb habe ich mich entschieden, bei dem Python Skipt zu bleiben und dieses nun von ChatGPT erweitern zu lassen, so dass bei einem Aufruf in einer Markdown-Datei nach der unsichtbaren Zeile %%insert%% (siehe auch den vorherigen Beitrag) das Ergebnis eingefügt wird.
Die vorgeschlagenen Lösungen konnte ich nicht verwenden, da ChatGPT nicht damit umgehen konnte, dass das Ergebnis des Skripts ein formatierter mehrzeiliger String war und die vorgeschlagenen Aufrufe mit sed oder awk einfach nicht damit umgehen konnten. Nachdem mir dann auch noch ein Perl-Aufruf als Lösung vorgeschlagen wurde, musste ich wieder selbst „kreativ” werden und Google bemühen. Als Lösung habe ich mich dann entschieden, das Markdown in einer temporären Datei zu speichern und diese an der entsprechenden Stelle in die Bookmark-Datei einzufügen. Dazu habe ich einen entsprechenden sed Befehl gefunden, der auch funktioniert hat.
Um es kurz zu machen, der endgültige Code, wie er jetzt im Alfred Workflow verwendet wird, sieht wie folgt aus:
#!/opt/homebrew/bin/python3
import sys
from linkpreview import link_preview
def generate_markdown_tile(url):
preview = link_preview(url, parser="lxml")
# Check if the image is None and replace it with a default image URL
if preview.image is None:
preview.image = "https://example.com/noimage.png"
markdown_tile = f"""
<table padding=50px>
<tr>
<td>
<img src="{preview.image}" alt="{preview.title}" width="200" style="padding: 10px;">
</td>
<td>
<a href="{url}" style="font-size: 16px;">{preview.title}</a>
<br>
<p>{preview.description}</p>
</td>
</tr>
</table>
"""
return markdown_tile
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python script_name.py <url>")
sys.exit(1)
url = sys.argv[1]
markdown_tile = generate_markdown_tile(url)
print(markdown_tile)
Ich habe auch die Formatierung des Eintrags geändert. Da Markdown keine verschachtelten Tabellen interpretieren kann, habe ich auf HTML umgestellt, das auch in Obsidian problemlos gerendert wird. Den Shebang musste ich einfügen, weil ich mit Python in Alfred Probleme hatte (s.u.).
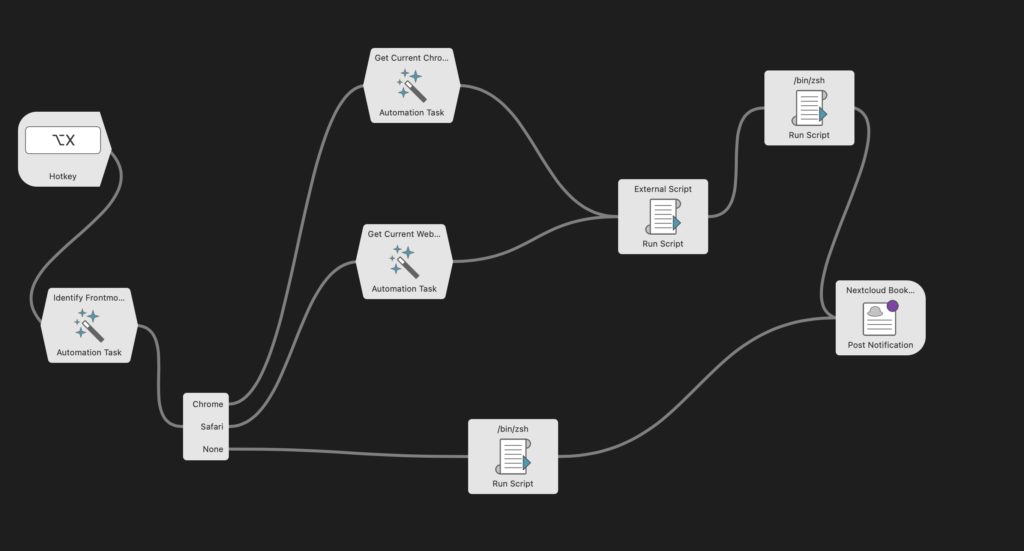
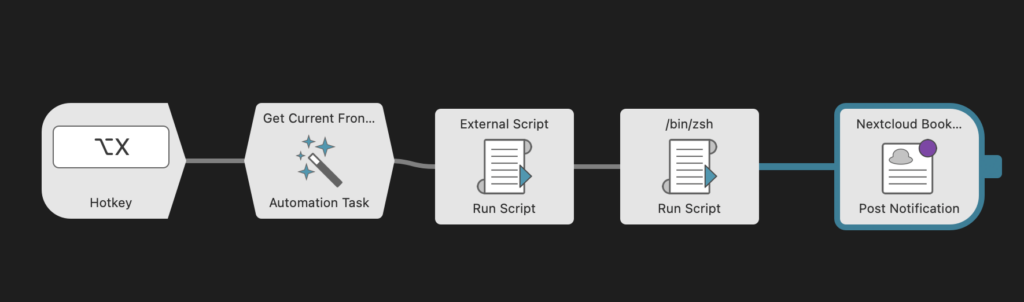
Im Prinzip ist der Ablauf ähnlich wie im vorherigen Artikel: Zuerst wird der aktive Browser abgefragt, dann wird aufgrund der Funktionsweise der Alfred-Module kurz nach Chrome und Safari ein separater Weg eingeschlagen, um die URL des aktiven Browserfensters abzufragen, die dann als Input für das obige Skript verwendet wird. Das Ergebnis wird dann an das folgende zsh-Skript übergeben, das den Eintrag in die entsprechende Datei in meinem Obsidian Vault schreibt:
# Replace with the actual variable content
markdown_callout="{query}"
# Source file containing content to insert
temp_md=$(mktemp)
echo "$markdown_callout" > "$temp_md"
# Destination file where content will be inserted
destination_file="/PathToMyVault/01 Documents/Bookmarks.md"
# Special string indicating the position to insert
insert_marker="%%ins%%"
# Create a temporary file to store modified content
temp_file=$(mktemp)
# Insert the content of temp_md into destination_file using sed
sed "/${insert_marker}/r ${temp_md}" "${destination_file}" > "${temp_file}"
# Replace the original destination_file with the modified content
mv "${temp_file}" "${destination_file}"
# Clean up temporary files
rm "$temp_md"
echo "Done"
Wahrscheinlich hätte ich diesen Teil auch im Python-Script machen können, aber da ich Probleme mit der Verwendung von Python in Alfred hatte, habe ich es bei dieser Lösung belassen (never change a running system). Das Problem ist einfach, dass wenn man Python als Sprache in der Scriptbox auswählt, immer das auf dem Mac installierte Python unter /usr/bin/python3 aufgerufen wird, das aber irgendwie auf Fehler läuft. Also habe ich das Script als externes Script eingebunden und mit dem shebang noch sichergestellt, dass auch das neuere von brew installierte Python unter /opt/homebrew/bin/python3 verwendet wird. Am einfachsten erstellt man ein externes Skript in der Skriptbox, wo man einfach einen Namen eingibt, dann wird diese Datei im Workflow-Ordner erstellt, wenn sie noch nicht existiert und über den Button „Skript öffnen” wird diese dann im bevorzugten Editor geöffnet und der Code kann hinein kopiert werden.
Jetzt werden meine Lesezeichen auf meiner Bookmarkseite in Obsidian etwas schöner angezeigt.
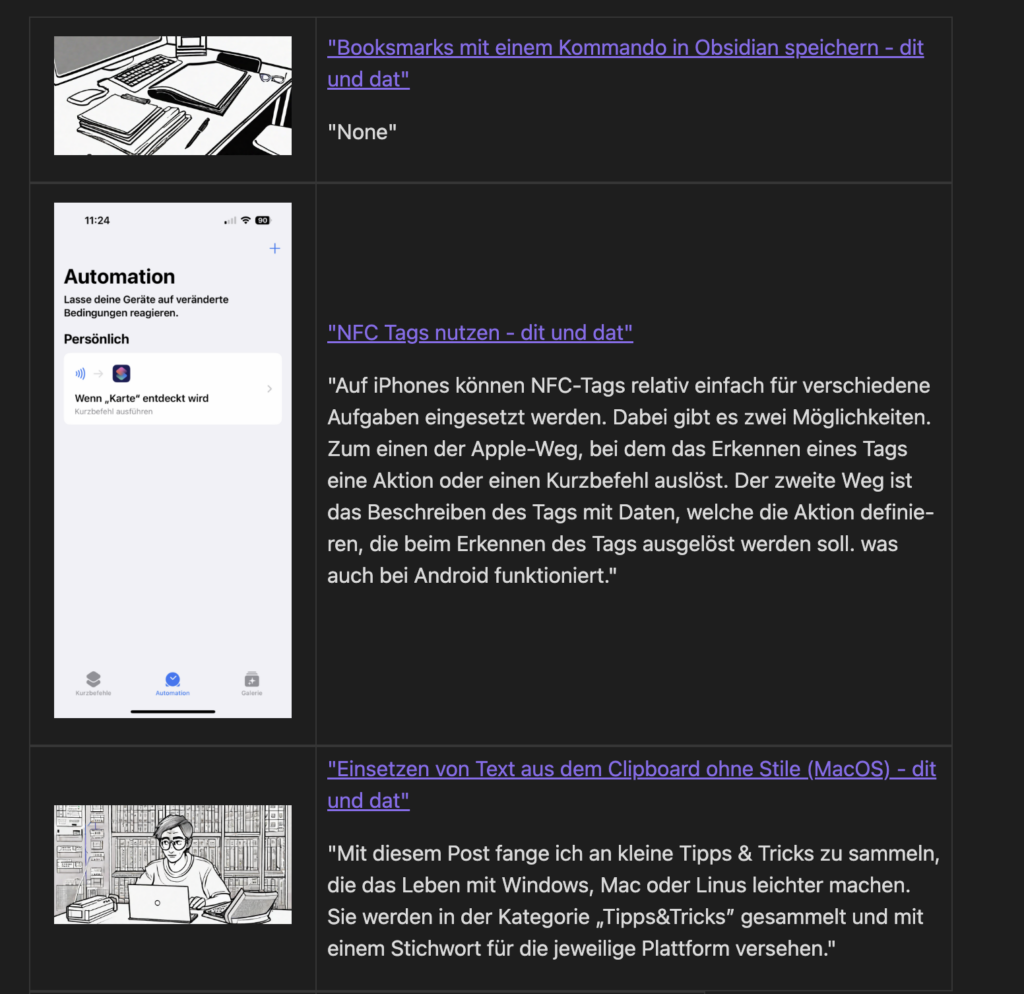
Leider gibt es zwei Probleme mit dieser Methode. Einige Websites scheinen es nicht zu mögen, wenn sie mit linkpreview aufgerufen werden. So kann ich mit diesem Skript z.B. die Seite https://www.cyberciti.biz nicht bookmarken. Ein zweites Problem ist in der Abbildung oben zu sehen. Meine WordPress Installation weigert sich, eine Zusammenfassung für neuere Artikel zu erstellen. Vielleicht ist das ein Fehler in der letzten Version von WordPress. In meinen RSS-Feed taucht der Text auf. Im Nachtrag stelle ich einen Workaround vor.
Nachtrag:
Das Problem mit den Websites, die sich weigern, ihre Geheimnisse preiszugeben, habe ich noch nicht gelöst, wahrscheinlich muss man eine Bibliothek verwenden, die den Browser-Agenten vortäuscht — da muss ich noch recherchieren. Aber ich habe einen Workaround für mein WordPress-Problem gefunden. Ich benutze nun doch Beautiful Soup, zumindest für den Teil, der einen Text als Zusammenfassung aufbereitet. Dazu habe ich das Skript von oben so erweitert, dass Beautiful Soup den ersten Absatz des Textes als Zusammenfassung extrahiert, falls linkpreview keinen Text übergeben bekommt. Ich habe zwar auch versucht, das ganze Skript mit Beautiful Soap zu realisieren, aber leider hat linkpreview das „richtigere” Bild gefunden und Beautiful Soups Bilder-Bild fand ich nicht gut. Also nutze ich ersteinmal beide Bibliotheken.
#!/opt/homebrew/bin/python3
import sys
from linkpreview import link_preview
import requests
from bs4 import BeautifulSoup
def get_first_paragraph(soup):
paragraph = soup.find('p')
if paragraph:
return paragraph.get_text().strip()
return "No excerpt available"
def generate_markdown_tile(url):
preview = link_preview(url, parser="lxml")
# Check if the image is None and replace it with a default image URL
if preview.image is None:
preview.image = "https://example.com/noimage.png"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
if not preview.description:
description = get_first_paragraph(soup)
else:
description = preview.description
markdown_tile = f"""
<table padding=50px>
<tr>
<td>
<img src="{preview.image}" alt="{preview.title}" width="200" style="padding: 10px;">
</td>
<td>
<a href="{url}" style="font-size: 16px;">{preview.title}</a>
<br>
<p>{description}</p>
</td>
</tr>
</table>
"""
return markdown_tile
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python script_name.py <url>")
sys.exit(1)
url = sys.argv[1]
markdown_tile = generate_markdown_tile(url)
print(markdown_tile)
Und so wird dann nun auch der fehlende Text angezeigt.

Das ist zwar ein wilder Hack, aber vielleicht finde ich ja auch noch eine bessere Lösung. Erstmal reicht es aber für mich voll aus.
Nachtrag 2:
Einen Tag nach der Veröffentlichung dieses Beitrages, wurde ich im Alfred Blog auf eine neuen Automative Task Gruppe aufmerksam gemacht, die einerseits den Alfred Workflow vereinfacht und auch erweitert, aber auch einen Nachteil hat.
Anstatt zuerst abzufragen, in welchem Browser der Hotkey gedruckt wurde, um die unterschiedlichen Routinen für Chrome- und Webkit-basierte Browser aufzurufen, gibt es nun einen neuen Automation Task „Get Current Frontmost Browser Tab”, der dies intern verarbeitet und die URL und/oder den Titel als Ausgabe liefert.
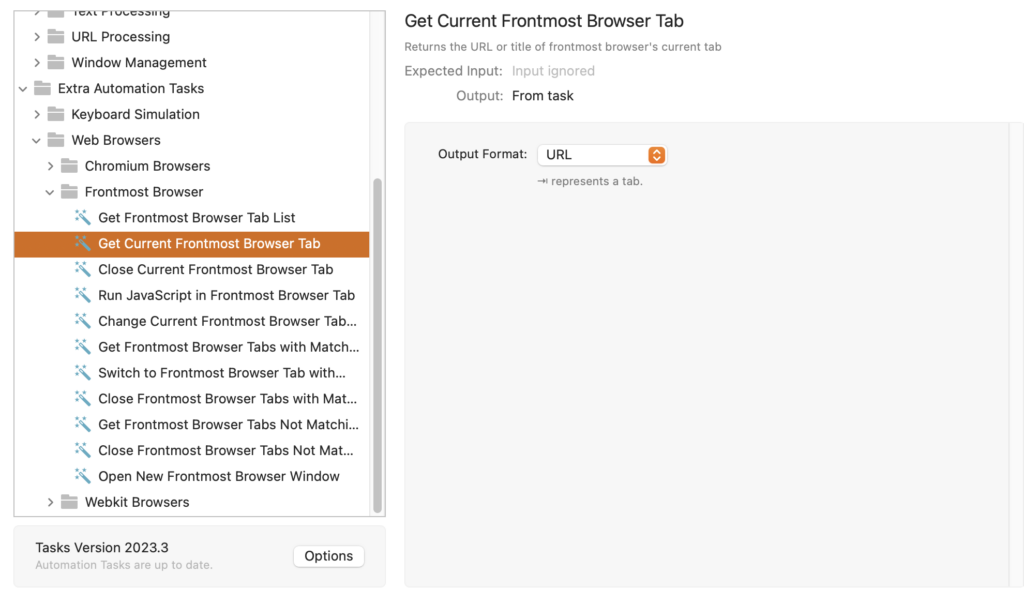
So kann ich den Workflow vereinfachen und er funktioniert nun ohne großen Aufwand in allen Browsern. Ein kleiner Nachteil ist, dass ich nicht abfragen kann, ob die App „frontmost” kein Browser ist, um einen Hinweis zu senden, dass der Workflow an dieser Stelle nicht funktioniert.
Das war’s. Wie immer, Verbesserungsvorschläge, Fragen oder Sonstiges bitte in den Kommentaren hinterlassen.
Schreibe einen Kommentar