

Einleitung
Wenn ich interessante Webseiten entdecke, nutze ich Bookmarks. Auf diesem Blog habe ich bereits zwei Methoden vorgestellt, wie ich mithilfe einfacher Tastenkürzel Bookmarks erstelle, die dann in Obsidian gespeichert werden. Diese Vorgehensweise ermöglicht es mir, meine Bookmarks unabhängig vom verwendeten Browser und der Plattform zentral zugänglich zu machen.
Die bisher vorgestellten Lösungen waren recht simpel: Entweder wurden die Bookmarks nur mit Datum, Titel und URL gespeichert oder in einer ansprechenderen Variante auch mit einem kleinen Vorschaubild und einem Auszug der Webseite, sofern verfügbar.
Ein Nachteil dieser Methoden ist jedoch, dass man – selbst in der erweiterten Variante – leicht den Überblick verlieren kann, warum eine Webseite als erinnerungswürdig eingestuft wurde. Manchmal sind Titel und Auszug ausreichend, oft jedoch nicht. Eine für mich praktikable Lösung besteht darin, zusätzlich einen Textauszug zu speichern, der mehr Kontext bietet als die anderen Methoden.
Ich möchte zwei Lösungen vorstellen, mit denen ich nun auf dem Mac sowie auf dem iPhone und iPad ein Bookmark zusammen mit einer Textauswahl von der Webseite in Obsidian ablegen kann. Das Vorgehen, das ich auf dem Mac mit der Alfred App und dem Powerpack nutze, stelle ich in diesem Beitrag etwas ausführlicher vor. Wie ich das für iOS/iPadOS handhabe, werde ich dann in einem zweiten Artikel vorstellen.
Warum zwei unterschiedliche Lösungen? Auf dem Mac nutze ich gerne verschiedene Browser. Alfred bietet eine Funktion, die es ermöglicht, JavaScript-Skripte in fast allen installierten Browsern zu starten. In den Apple-Kurzbefehlen ist das Starten von JavaScript-Skripten leider nur im Safari-Browser möglich. Allerdings benötig am Ende das JavaScript nur eine minimale Anpassung um in einem Kurzbefehl verwendet werden kann.
Was soll erreicht werden
Mein Ziel ist es, aus einer solchen Markierung im Browser:

auf einer definierten Notiz in meinem Obsidian Vault einen solchen Eintrag hinzuzufügen:
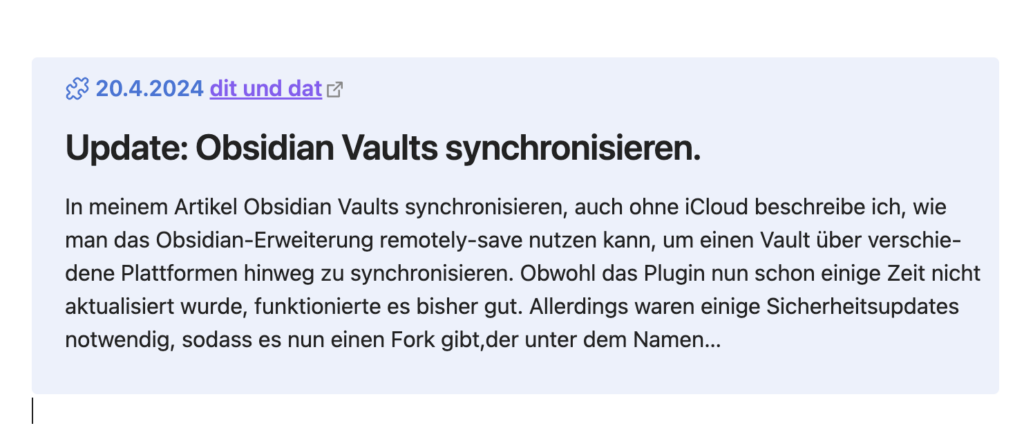
Wie ich bereits erwähnt habe, basiert der Teil, der die Markierung im Browser verarbeitet, auf JavaScript. Bei meiner Suche im Web hat sich die Verwendung von JavaScript als die beste Lösung herausgestellt, da es speziell dafür entwickelt wurde, Inhalte auf Webseiten zu manipulieren.
Allerdings muss dafür in den Browsern die Ausführung von JavaScript erlaubt sein. Beim Safari-Browser findet man diese Einstellung im Tab „Sicherheit”. In anderen Browsern kann man sie beispielsweise im Menü „Anzeigen → Entwickler” aktivieren.
Ansonsten wird für die Umsetzung die Alfred App sowie das Powerpack benötigt. Zusätzlich muss für den zweiten Teil des Workflows Python auf dem Mac installiert sein.
1. Schritt: Das JavaScript
Meine JavaScript-Kenntnisse beschränken sich auf grundlegende Prinzipien und Anwendungsfälle, also gehen praktisch gegen Null. Daher benötigte ich für die Erstellung des notwendigen Codes, um die Textauswahl in einem Browser zu verarbeiten, Hilfe. Wie schon so oft, griff ich dafür auf ChatGPT zurück, und nach einigen Runden haben wir einen „Working Code” erstellt:
/**
* Extracts the currently selected HTML from the browser window.
* @returns {string} The HTML string of the selected content.
*/
function getSelectionHtml() {
// console.log("Attempting to get the current selection...");
let html = "";
if (window.getSelection) {
const sel = window.getSelection();
// console.log(`Selection object obtained: ${sel.toString()}`);
if (sel.rangeCount) {
// console.log(`Number of selection ranges: ${sel.rangeCount}`);
const container = document.createElement("div");
for (let i = 0, len = sel.rangeCount; i < len; ++i) {
container.appendChild(sel.getRangeAt(i).cloneContents());
// console.log(`Contents of range ${i} appended to container.`);
}
html = container.innerHTML;
// console.log("Final HTML content extracted from selection:");
// console.log(html);
} else {
// console.log("No ranges in the selection.");
}
} else {
// console.log("window.getSelection is not supported by this browser.");
}
return html;
}
/**
* Converts HTML content into Markdown.
* @param {string} html - HTML content to be converted.
* @returns {string} The converted Markdown.
*/
function convertHtmlToMarkdown(html) {
// console.log("Starting conversion of HTML to Markdown...");
const doc = new DOMParser().parseFromString(html, 'text/html');
let markdown = convertNode(doc.body);
// console.log("Markdown conversion completed:");
// console.log(markdown);
return markdown.trim();
}
/**
* Converts an HTML node to its Markdown representation.
* @param {Node} node - The HTML node to convert.
* @returns {string} Markdown representation of the node.
*/
function convertNode(node) {
// console.log(`Converting node: ${node.nodeName}`);
let markdown = '';
if (node.nodeType === Node.ELEMENT_NODE) {
// console.log(`Processing element node: ${node.tagName}`);
switch (node.tagName) {
case 'H1': case 'H2': case 'H3': case 'H4': case 'H5': case 'H6':
markdown += `${'#'.repeat(parseInt(node.tagName[1]))} ${node.textContent.trim()}\n\n`;
break;
case 'P':
markdown += `${node.textContent.trim()}\n\n`;
break;
case 'A':
markdown += `[${node.textContent}](${node.href})`;
break;
case 'UL': case 'OL':
markdown += convertList(node);
break;
case 'IMG':
const alt = node.alt || 'Image';
const src = node.src || '';
const title = node.title ? ` "${node.title}"` : '';
markdown += `\n`;
break;
case 'PRE': case 'CODE':
markdown += `\`\`\`\n${node.textContent}\n\`\`\`\n\n`;
break;
case 'TABLE':
markdown += convertTableToMarkdown(node);
break;
default:
node.childNodes.forEach(child => {
markdown += convertNode(child);
});
break;
}
} else if (node.nodeType === Node.TEXT_NODE && node.textContent.trim()) {
// console.log(`Adding text node content: ${node.textContent.trim()}`);
markdown += node.textContent.trim() + ' ';
}
return markdown;
}
/**
* Converts HTML lists to Markdown.
* @param {HTMLElement} list - The list element.
* @returns {string} Markdown formatted list.
*/
function convertList(list) {
// console.log(`Converting ${list.tagName} to Markdown list...`);
let markdown = '';
const items = list.children;
for (let item of items) {
if (item.tagName === 'LI') {
const prefix = list.tagName === 'OL' ? (Array.from(list.children).indexOf(item) + 1) + '.' : '-';
markdown += `${prefix} ${item.textContent.trim()}\n`;
}
}
return markdown + '\n';
}
/**
* Converts HTML tables to Markdown.
* @param {HTMLTableElement} table - The table element.
* @returns {string} Markdown formatted table.
*/
function convertTableToMarkdown(table) {
// console.log(`Converting table to Markdown...`);
let markdown = '';
const rows = table.querySelectorAll('tr');
rows.forEach((row, index) => {
let rowMarkdown = '|';
row.querySelectorAll('th, td').forEach(cell => {
rowMarkdown += ` ${cell.textContent.trim()} |`;
});
markdown += rowMarkdown + '\n';
// Add header separator for the first row if it contains headers
if (index === 0 && row.querySelector('th')) {
markdown += '|' + Array.from(row.children).map(() => ' --- ').join('|') + '|\n';
}
});
return markdown + '\n';
}
/**
* Main function that orchestrates the conversion from HTML to Markdown.
* @returns {void}
*/
function main() {
// console.log("Main function started...");
const html = getSelectionHtml();
if (!html) {
// console.error('No HTML content selected or script failed to access selection.');
return;
}
let markdown = convertHtmlToMarkdown(html);
const datum = new Date().toLocaleDateString();
const title = document.title;
const url = window.location.href;
const header = `\n\n>[\!snippets] ${datum} [${title}](${url})\n`;
markdown = markdown.split('\n').map(line => '> ' + line).join('\n');
markdown = header + markdown;
// console.log(`Final Markdown output: ${markdown}`);
return (markdown);
}
main();
ChatGPT war so nett, den Code mit Kommentaren zu versehen, die die wichtigsten Funktionen des Skripts erläutern. Ich hoffe, es ist in Ordnung, dass diese Kommentare auf Englisch verfasst sind. Zudem wurden Logging-Befehle integriert, die es ermöglichen, die Ausführung des Skriptes in der Konsole der Browser-Entwicklertools zu verfolgen. Im obigen Code sind diese jedoch auskommentiert. Falls gewünscht, können sie aktiviert werden indem ‘// console.log’ durch ‘console.log’ in einem Text Editor mit der Suchen und Ersetzen Funktion ausgetauscht wird.
Was macht der Code?
Da ich nicht nur einfach den Code verwenden möchte, sondern die Funktionsweise in JavaScript verstehen will, bat ich ChatGPT, mir eine detaillierte Erklärung der einzelnen Funktionen zu geben. Es bedurfte zwar auch einiger Nachfragen, doch in den folgenden Absätzen möchte ich aufzeigen, was ich letztendlich verstanden habe. Ich hoffe, die Erklärungen sind einigermaßen korrekt und ebenso lehrreich wie für mich. Es ist aber durchaus o.k, diesen Teil zu Überspringen und direkt zum Schritt 2 zu springen.
1. getSelectionHtml()
function getSelectionHtml() {
// console.log("Attempting to get the current selection...");
let html = "";
if (window.getSelection) {
const sel = window.getSelection();
// console.log(`Selection object obtained: ${sel.toString()}`);
if (sel.rangeCount) {
// console.log(`Number of selection ranges: ${sel.rangeCount}`);
const container = document.createElement("div");
for (let i = 0, len = sel.rangeCount; i < len; ++i) {
container.appendChild(sel.getRangeAt(i).cloneContents());
// console.log(`Contents of range ${i} appended to container.`);
}
html = container.innerHTML;
// console.log("Final HTML content extracted from selection:");
// console.log(html);
} else {
// console.log("No ranges in the selection.");
}
} else {
// console.log("window.getSelection is not supported by this browser.");
}
return html;
}
Das Skript verwendet die Funktion getSelectionHtml(), um das HTML der aktuellen Markierung im Browser zu übernehmen. Mit dem Statement if(window.getSelection), wird zunächst sichergestellt, dass der Browser diese Funktion überhaupt unterstützt. Sollte das nicht der Fall sein, wird der else-Teil des Codes ausgeführt, der in hier im Moment nur einen auskommentierten Befehl für das Debugging enthält. Andernfalls wird das sel-Objekt mit der Browser-Markierung befüllt. Die nachfolgende Abfrage if (sel.rangeCount) prüft, ob überhaupt etwas ausgewählt wurde. Der rangeCount enthält die Anzahl der zusammenhängenden Markierungsbereiche, die dann in der folgenden for-Schleife bearbeitet werden. Wenn nichts im Browser ausgewählt ist, steht im rangeCount eine 0 und der else-Fall wird ausgeführt. In allen anderen Fällen wird die for-Schleife durchlaufen, obwohl diese eigentlich nicht notwendig ist, da ich das Skript nur in modernen Browsern verwende, die zu diesem Zeitpunkt keine Möglichkeit bieten, mehrere Bereiche, wie z.B. in Word, zu markieren. Also steht im rangeCount immer entweder eine 0 oder eine 1.
Diese beiden if-Statements machen den Code etwas komplexer, weil sie eigentlich nicht notwendig sind, aber ich habe mich entschieden, sie zu behalten, um eine generelle JavaScript Frage zu klären, die mich anfangs etwas verwirrte. Die for-Schleife startet mit einem Counter von 0 und wird nur einmal durchlaufen, da ((let i = 0, len = sel.rangeCount; i < len; ++i) bedeutet, starte mit 0 und ende bei 1–1, also ebenfalls 0. Ich hätte erwartet, dass die Schleife bei 1 beginnt, also mit dem Wert des rangeCount, und dann das Abbruchkriterium eher i = len gewesen wäre. Warum also wird die Schleife mit dem Zähler i=0 gestartet? Die Lösung ist ganz einfach: Bei Konstrukten wie Arrays oder Listen hat das erste Element den Index 0 und nicht 1. So wird in dem Statement container.appendChild(sel.getRangeAt(i).cloneContents()); dann das erste Element dem Objekt container zugeordnet, in dem die Markierung steht, da i=0 ist. Das ginge zwar auch anders, aber es scheint guter JavaScript-Stil zu sein, die 1 nicht innerhalb der for-Schleife von i abzuziehen.
Das Objekt container wurde vor der Schleife als Dokument mit einem <div> initialisiert. An dieses <div> wird dann der HTML-Code der Markierung erst angehängt und dann wiederum mit der Zeile vor der Zuordnung zur Variablen html = container.innerHTML; abgehängt. Dieser Schritt soll laut ChatGPT helfen, aus dem String des HTML-Fragment eine saubere HTML-Struktur zu machen, auch wenn am Ende wieder ein String als Resultat ausgegeben wird.
Der vereinfachte Funktionscode würde übrigens so aussehen:
function getSelectionHtml() {
let html = "";
const sel = window.getSelection();
if (sel.rangeCount > 0) {
const container = document.createElement("div");
container.appendChild(sel.getRangeAt(0).cloneContents());
html = container.innerHTML;
}
return html;
}
Für mich werde ich eher den komplexeren Code durch eine bessere Ausnahmebehandlung erweitern. — aber nicht an dieser Stelle.
2. convertHtmlToMarkdown(html)
function convertHtmlToMarkdown(html) {
const doc = new DOMParser().parseFromString(html, 'text/html');
let markdown = convertNode(doc.body);
return markdown.trim();
Mit dieser kleine Funktion wird die Konvertierung vorbereitet. In der Zeile
const doc = new DOMParser().parseFromString(html, 'text/html');
wird mit dem HTML-Fragment ein neues DOM-Objekt erstellt. DOM ist die Abkürzung von „Document Objekt Model und stellt das HTML als Baustruktur zu Verfügung, für das JavaScript einfache Verarbeitungsfunktionen bietet.
Im nächsten Schritt wird mit dem Aufruf let markdown = convertNode(doc.body); der Teil des DOM-Objektes an die Konvertierungsfunktion übergeben, wobei nur der body des gesamten HTML-Dokuments übergeben wird. Prinzipiell besteht das DOM einer Webseite aus weiteren Teilen, wie dem head-Teil. Dieser Aufruf stellt sicher, dass nur der „sichtbare Teil” übergeben wird. Das Ergebnis, das aus der Konvertierung entstandene Markdown, wird dann der Variablen markdown übergeben und mit der Methode trim() von eventuellen überflüssigen Leerzeichen befreit, bevor es als Ergebnis ausgegeben wird.
3. convertNode(node), convertList(list) und convertTableToMarkdown(table)
function convertNode(node) {
// console.log(`Converting node: ${node.nodeName}`);
let markdown = '';
if (node.nodeType === Node.ELEMENT_NODE) {
// console.log(`Processing element node: ${node.tagName}`);
switch (node.tagName) {
case 'H1': case 'H2': case 'H3': case 'H4': case 'H5': case 'H6':
markdown += `${'#'.repeat(parseInt(node.tagName[1]))} ${node.textContent.trim()}\n\n`;
break;
case 'P':
markdown += `${node.textContent.trim()}\n\n`;
break;
case 'A':
markdown += `[${node.textContent}](${node.href})`;
break;
case 'UL': case 'OL':
markdown += convertList(node);
break;
case 'IMG':
const alt = node.alt || 'Image';
const src = node.src || '';
const title = node.title ? ` "${node.title}"` : '';
markdown += `\n`;
break;
case 'PRE': case 'CODE':
markdown += `\`\`\`\n${node.textContent}\n\`\`\`\n\n`;
break;
case 'TABLE':
markdown += convertTableToMarkdown(node);
break;
default:
node.childNodes.forEach(child => {
markdown += convertNode(child);
});
break;
}
} else if (node.nodeType === Node.TEXT_NODE && node.textContent.trim()) {
// console.log(`Adding text node content: ${node.textContent.trim()}`);
markdown += node.textContent.trim() + ' ';
}
return markdown;
}
Hier passiert die eigentliche Arbeit. Die Funktion convertNode(node) ruft sich selbst immer wieder rekursiv, im default-case des switch, auf und durchläuft so den Baum, also das DOM, Knoten für Knoten. Dabei fügt sie die entsprechende Markdown-Konvertierung zur Variable markdown hinzu. Ich beschränke mich auf die folgenden HTML-Tags:
<H1>bis<H6><p><a><img><pre>und<code><ul>und<ol><table>
Die HTML-Tags <table>, <ul> und <ol> werden jedoch nicht direkt innerhalb der Funktion convertNode(node) konvertiert, sondern dafür werden spezialisierte, etwas komplexere Funktionen aufgerufen. Für die Listen ist die entsprechende Funktion:
function convertList(list) {
// console.log(`Converting ${list.tagName} to Markdown list...`);
let markdown = '';
const items = list.children;
for (let item of items) {
if (item.tagName === 'LI') {
const prefix = list.tagName === 'OL' ? (Array.from(list.children).indexOf(item) + 1) + '.' : '-';
markdown += `${prefix} ${item.textContent.trim()}\n`;
}
}
return markdown + '\n';
}
Die Funktion erhält das List-Objekt als Eingabe, welches den zu konvertierende HTML-Listen-Teilbau enthält. Dies kann sowohl eine geordnete Liste (<ol>) als auch eine ungeordnete Liste (<ul>) beinhalten oder auch getestete Listen. Nach der Initialisierung der Variablen markdown, die nach und nach gefüllt wird, wird eine for-Schleife durchlaufen, in der auf die Unterknoten des Listen-Elements zugegriffen wird (list.children). Diese Unterknoten sollten die Listeneinträge (<li>) enthalten.
Abhängig vom Listentyp wird jedes Listenelement entweder mit einer fortlaufenden Nummer und einem Punkt im Falle von <ol> oder mit einem Bindestrich im Falle von <ul> in die Variable markdown eingefügt.
Nachdem das Array mit den Items durchlaufen ist, wird das resultierende Markup als Ergebnis zurückgegeben.
Die Abarbeitung eines <table-Tags ist etwas komplizierter:
function convertTableToMarkdown(table) {
// console.log(`Converting table to Markdown...`);
let markdown = '';
const rows = table.querySelectorAll('tr');
rows.forEach((row, index) => {
let rowMarkdown = '|';
row.querySelectorAll('th, td').forEach(cell => {
rowMarkdown += ` ${cell.textContent.trim()} |`;
});
markdown += rowMarkdown + '\n';
// Add header separator for the first row if it contains headers
if (index === 0 && row.querySelector('th')) {
markdown += '|' + Array.from(row.children).map(() => ' --- ').join('|') + '|\n';
}
});
return markdown + '\n';
}
In dieser Funktion wird das table-Objekt übergeben. Zunächst wird die Variable markdown initialisiert, in der das Ergebnis jedes Konvertierungsschrittes gesammelt und schließlich als Resultat zurückgegeben wird. Mit dem Aufruf table.querySelectorAll('tr') werden alle Zeilen (<tr>-Elemente) der Tabelle abgerufen. Dieser Schritt erfasst alle horizontalen Reihen der Tabelle, unabhängig davon, ob sie Kopfzeilen (<th>) oder normale Zelleneinträge (<td>) enthalten, und fügt sie als Array dem Objekt row hinzu. Anschließend wird jede Zeile der Tabelle einzeln durchlaufen. Für jede Zeile wird eine neue Variable rowMarkdown initialisiert, die mit einem Pipe-Symbol | beginnt, was in Markdown eine Tabellenzelle markiert. Innerhalb jeder Zeile werden mittels der Funktion row.querySelectorAll('th, td') alle Zellen abgerufen, und für jede Zelle wird der getrimmte Textinhalt gefolgt von einem abschließenden Pipe-Symbol | zu rowMarkdown hinzugefügt. Nun wird das Ergebnis jeder Zeilenverarbeitung an die Variable markdown angehängt, gefolgt von einem Zeilenumbruch \n, um die nächste Zeile der Markdown-Tabelle zu beginnen. Zeilen, die Kopfzeilen enthalten (<th>), werden speziell behandelt, indem eine Zeile mit der Markdown-Syntax für die Trennlinie unter den Zellen eingefügt wird.
4. main()
Die Funktion main()ist die Steuerungszentrale. Sie wird als erstes Aufgerufen, wenn das Skript gestartet wird.
function main() {
// console.log("Main function started...");
const html = getSelectionHtml();
if (!html) {
// console.error('No HTML content selected or script failed to access selection.');
return;
}
let markdown = convertHtmlToMarkdown(html);
const datum = new Date().toLocaleDateString();
const title = document.title;
const url = window.location.href;
const header = `\n\n>[\!snippets] ${datum} [${title}](${url})\n`;
markdown = markdown.split('\n').map(line => '> ' + line).join('\n');
markdown = header + markdown;
// console.log(`Final Markdown output: ${markdown}`);
return (markdown);
}
Zunächst wird die Konstante html mit dem Ergebnis des Aufrufes der Funktion getSelectionHtml() initialisiert. Die if-Abfrage sollte zur Fehlerbehandlung dienen, wenn nichts ausgewählt wurde, worauf ich im Moment noch verzichte.
Das HTML-Fragment wird dann der Konvertierungsfunktion übergeben, und deren Ergebnis wird in der Variablen markdown gespeichert.
Da ich als Ergebnis ein Markdown haben möchte, das in etwa so aussieht:
>[!snippets] 24.4.2024 [dit und dat](https://ileif.de/) > ## Update: Obsidian Vaults synchronisieren. > > In meinem Artikel Obsidian Vaults synchronisieren, auch ohne iCloud beschreibe ich, wie man das Obsidian-Erweiterung remotely-save nutzen kann, um einen Vault über verschiedene Plattformen hinweg zu synchronisieren. Obwohl das Plugin nun schon einige Zeit nicht aktualisiert wurde, funktionierte es bisher gut. Allerdings waren einige Sicherheitsupdates notwendig, sodass es nun einen Fork gibt,der unter dem Namen…
Die erste Zeile des Snippets-Markdowns wird in der Zeile
const header = \n\n>[\!snippets] ${datum} [${title}](${url})\n;
zusammengebaut und in der Konstanten header gespeichert, wobei noch die zuvor initialisierten Variablen datum, title und url verwendet werden. Das [!snippets] ist ein von mir definierter Callout-Typ. Wie das funktioniert, beschreibe ich kurz unten im Text. Es würde auch z.B. [\!info] oder ein ähnlicher tordefinierter Callout-Typ gehen. Der Backslash \ vor dem ! war notwendig, weil das ! ohne das Fluchtsymbol Fehler produzierte. Die zwei \n\n vor dem >[\!snippets] dienen zur visuellen Trennung der Blöcke in der Obsidian-Notiz.
Bevor nun die Teile zusammengefügt werden, wird noch das Ergebnis der Funktion getSelection für ein Callout aufbereitet, indem jeder Zeile ein > vorangestellt wird. Was mit der Zeile
markdown = markdown.split('\n').map(line => '> ' + line).join('\n');
passiert, zeigt wieder die Stärke von JavaScript bei der Manipulation von Objekten: Die Methode split erstellt aus jeder Zeile des HTML-Codes ein Item in einem Array, wobei das \n als Trennungszeichen definiert ist. Mit map wird dann jeder Zeile ein > vorangestellt und am Ende mit join das Ganze wieder als ein String zusammengebaut und die Zeilenumbrüche mit \n wieder eingefügt.
Zu guter Letzt werden die Variablen header und markdown zusammengefügt und als Ergebnis ausgegeben.
Schritt 2: Das Markdown Snippet in eine Obsidian Datei einfügen
Im ersten Teil wurde aus der Markierung im Browser ein Markdown erstellt, das nun im zweiten Schritt in eine vorhandene Obsidian-Notiz eingefügt werden soll. Dafür verwende ich ein kleines Python-Skript, das diese Verarbeitung direkt in der entsprechenden Datei vornimmt.
In meinem Fall heißt die Datei Snippet.md und ist in meinem Vault abgelegt, also beispielsweise unter /Users/Documents/ObsidianVault/Snippets.md. Da auch in dieser Datei am Anfang ein Bereich für die Meta-Daten der Notiz, das sogenannte Frontmatter, steht und ich eine Sortierung von „neu” nach „alt” bevorzuge, benötige ich einen Marker, der den Ort bezeichnet, an dem das Snippet direkt hinter dem Frontmatter eingefügt wird. Eigentlich bevorzuge ich einen Markdown-Ausdruck wie %%ins%%, der den Marker nur im Editier-Modus anzeigt. Da ich jedoch auch von iOS aus auf diese Datei zugreife und Snippets hinzufüge, sind die Möglichkeiten begrenzt. In meinem nächsten Beitrag werde ich dies ausführlicher erläutern. Die Kurzbefehle auf iOS erlauben nur das Einfügen hinter einer Überschrift. Deshalb nutze ich ###### Snippets als Marker.
Und so sieht der entsprechende Code aus:
import sys
def insert_snippet(file_path, insert_marker, snippet):
with open(file_path, 'r', encoding='utf-8') as file:
content = file.readlines()
new_content = []
insert_done = False
for line in content:
new_content.append(line)
# Check if this line contains the insertion marker and we haven't inserted yet
if insert_marker in line and not insert_done:
# Replace escape sequences for newlines and append the snippet
formatted_snippet = snippet.replace(r'\\n', '\n')
new_content.append(formatted_snippet + '\n')
insert_done = True
# Rewrite the modified content back to the file
with open(file_path, 'w', encoding='utf-8') as file:
file.writelines(new_content)
if __name__ == '__main__':
if len(sys.argv) != 2:
print("Usage: python script.py <snippet>")
sys.exit(1)
snippet = sys.argv[1]
file_path = "/path_to_my/Vault/Snippets.md"
insert_marker = '###### Snippets'
insert_snippet(file_path, insert_marker, snippet)
Dieses Skript is auch relativ einfach aufgebaut. Das Skript wird mit dem aus dem ersten Teil generierten Markdown-String aufgerufen und verarbeitet diesen in der Funktion Insertion_snippet. Im untern wird geprüft, ob die Funktion tatsächlich mit einem String als Argument aufgerufen wird, falls nicht steigt da Skript einfach aus. Ausser wird hier der Pfad zu der Notizdatein in den Variablen file_path und der Marker in der Variablen insert_marker festgelegt. Mit diesen drei Parameter, wird dann die eigentlich Routine aufgerufen, die das Snippet einfügt.
insert_snippet(file_path, insert_marker, snippet)
def insert_snippet(file_path, insert_marker, snippet):
with open(file_path, 'r', encoding='utf-8') as file:
content = file.readlines()
new_content = []
insert_done = False
for line in content:
new_content.append(line)
# Check if this line contains the insertion marker and we haven't inserted yet
if insert_marker in line and not insert_done:
# Replace escape sequences for newlines and append the snippet
formatted_snippet = snippet.replace(r'\\n', '\n')
new_content.append(formatted_snippet + '\n')
insert_done = True
# Rewrite the modified content back to the file
insert_done
Zuerst wird die Datei geöffnet und jede Zeile als separates Element in der Liste content abgespeichert. Eine neue Liste new_content wird initialisiert, die den durch das Snippet ergänzten Dateiinhalt aufnimmt. Zusätzlich wird insert_done mit False initialisiert, um sicherzustellen, dass das Snippet nur hinter dem ersten Auftreten des Markers eingefügt wird.
In der for-Schleife wird jede Zeile von content iteriert und in die neue Liste new_content eingefügt. Mit der Bedingung if insert_marker in line and not insert_done: wird geprüft, ob in der aktuellen Zeile der Marker vorhanden ist und ob insert_done noch immer False ist. Wenn diese Bedingungen erfüllt sind, wird das Snippet in die new_conten eingefügt.
Das Skript trifft dabei Vorsichtsmaßnahmen wie das Ersetzen von \\n durch echte Zeilenumbrüche \n. Nach dem Einfügen des Snippets wird insert_done auf True gesetzt, um weitere Einfügungen zu verhindern. Die verbleibenden Zeilen von content werden dann weiterhin zu new_content hinzugefügt.
Am Ende wird mit dem die Datei Snippets.md erneut geöffnet, der vorhandene Inhalt gelöscht und mit file.writelines(new_content) wird der aktualisierte Inhalt, einschließlich des eingefügten Snippets, zurückgeschrieben:
with open(file_path, 'w', encoding='utf-8') as file:
file.writelines(new_content)
Damit sind die beiden Skripte definiert und in dem Schritt 3 werden sie als Alfred Workflow zusammen gebaut.
Schritt 3: Alfred Workflow
Die Definition des Alfred-Workflows erfolgt in drei einfachen Schritten:
- Als Trigger „Hotkey” zu der Aktion verwenden.
- Den Automation Task -”Run JavaScript in Front Browser Tab“ auswählen und das JavaScript einfügen
- Eine “Run Script”-Aktion hinzufügen und in diese das Python-Skript einfügen.
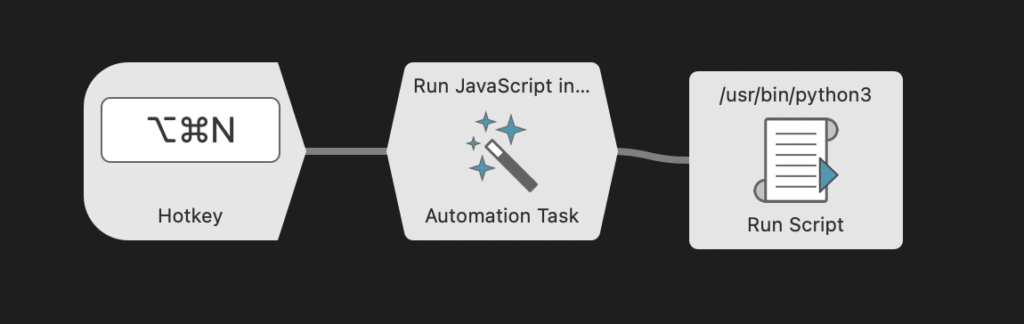
Das war dann im Prinzip alles. Falls irgendetwas nicht funktioniert, können die // console.log-Anweisungen im JavaScript-Teil wieder auskommentiert werden. Dadurch lässt sich in der Konsole der Entwicklertools im Browser nachvollziehen, wo möglicherweise Probleme auftreten.
Defineren eigener Callout Typen
Wie versprochen folgt am Ende ein kleiner Exkurs, wie man eigene Callout-Typen in Obsidian definieren kann. Dazu wird ein wenig CSS benötigt:
.callout[data-callout="snippets"] {
--callout-color: 61, 118, 218;
--callout-icon: puzzle;
}
Dieser CSS-Code muss in Obsidian in einem CSS-Snippet gespeichert sein, was ganz einfach umzusetzen ist. Gehen Sie dazu wie folgt vor:
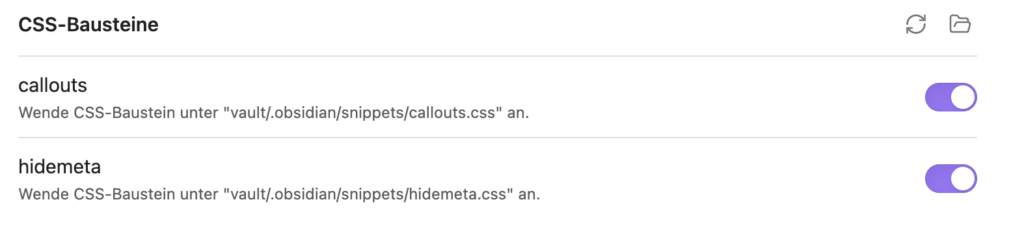
- Unter den „Darstellung“-Einstellungen -> CSS-Bausteine auf das Ordnersymbol klicken.
- In dem sich öffnenden Ordner eine Datei mit einem aussagekräftigen Namen, z.B.
callout.css, erstellen. - Die oben beschriebene CSS-Definition in diese Datei einfügen und speichern.
- Anschließend auf das „Refresh“-Icon klicken, um die neu erstellte Datei zu aktivieren.
Für die Icons empfiehlt es sich, Lucide Icons zu nutzen. In das Callout-CSS kann einfach der Name des gewünschten Icons eingetragen werden. Ich verwende hier das Puzzle-Icon.
Schlusswort
Damit wäre die Lösung unter Alfred komplett dargestellt. Ich hoffe, es war lehrreich, denn ich habe – auch für mich selbst – den von ChatGPT und mir erarbeiteten Code nicht nur überflogen, sondern jede Zeile genau betrachtet und erklären lassen. Die Erklärungen von ChatGPT habe ich nicht einfach übernommen, sondern – um auch selbst zu lernen – in meine eigenen Worte gefasst. Ich entschuldige mich bei allen Informatikern und Fachleuten, falls ich einige Begriffe vielleicht nicht ganz korrekt verwendet habe. Ich freue mich auf Korrekturen, Kritik und weitere Kommentare.
In den nächsten Tagen folgt dann auch eine Lösung für das iPhone und das iPad, die etwas kürzer ausfallen wird, da das JavaScript fast ohne Änderung übernommen werden kann. Mich würde auch interessieren, ob dieses Vorgehen auch in Raycast implementiert werden kann. Falls jemand dazu Informationen oder Tipps hat, freue ich mich über Kommentare dazu.
Schreibe einen Kommentar