

Ich nutze Large Language Modelle (LLM), also KI-Services, bei der Erstellung meiner kleinen Skripte, aber auch zur Textkorrektur und schließlich für die Artikelbilder in diesem Blog. Einige Modelle, wie Stable Diffusion für die Bilderstellung, laufen lokal, aber ich nutzte bisher vor allem auch ChatGPT und andere webbasierte LLMs für meine Zwecke.
Vor ein paar Wochen hatte ich schon Ollama auf meinem Mac installiert, aber dann nicht weiter damit gearbeitet. Die Ankündigungen von Apple, mehr auf lokale LLMs zu setzen, haben mich dann bewogen, mich doch etwas intensiver mit Ollama als lokale KI zu beschäftigen.
Ich schreibe hier als naiver Anwender ohne tiefere Kenntnisse der technischen Hintergründe. Ich verwende LLMs „out of the box“ und lasse viele der einstellbaren Parameter auf den Standardeinstellungen. In diesem Beitrag möchte ich lediglich zeigen, wie einfach es ist, LLM-Modelle mit den entsprechenden Tools zu installieren und zu nutzen.
Noch ein kurzes Wort zu den Voraussetzungen. Ich habe dies alles auf einem MacBook Pro M1 mit 16 GB Hauptspeicher getestet. Damit konnte ich mit einfachen Modellen arbeiten und auch nebenher z.B. Obsidian, das viel Speicher benötigt, nutzen. Ich habe Ollama auch auf einem kleinen MacBook Air M1 mit 8 GB zum Laufen bekommen, aber das würde ich nicht unbedingt zum Arbeiten empfehlen, da der Rechner warm wird und die Lüfter am Pro schon (leise) zu laufen beginnen.
Was ist Ollama?
Ollama ist eine Plattform, die es ermöglicht, unter Windows, Linux und macOS lokale LLMs zu installieren und zu verwalten. Dies geschieht ebenso wie das Chatten im Terminal-Programm auf der Kommandozeile. Daneben läuft aber auch ein Service, der über eine Schnittstelle angesprochen werden kann. Es gibt so einige Anwendungen, die diesen Service nutzen und den Chat sowie einige Einstellungen in einer grafischen Benutzeroberfläche ermöglichen. Auch gibt es einige Plugins für Programme wie Obsidian, die einen Zugriff auf die „KI“ innerhalb des Programms über diese Schnittstelle ermöglichen.
Neben Ollama bieten auch andere ähnliche Plattformen die Möglichkeit, lokale Modelle einfach zu installieren und mit ihnen zu arbeiten. Eines davon ist Pinokio, mit dem eine Vielzahl von Tools und Modellen, auch zur Bilderstellung, adminstrert werden können. Mit GPT4all oder dem LM Studio lassen sich zwar nur Sprachmodelle verwalten, aber diese Tools bieten zusätzlich ein integriertes Chat-Interface. In diesem Artikel gehe ich jedoch nur auf Ollama ein, da ich damit nicht nur einige Modelle installieren kann, sondern je nach Anwendung einen UI-Client, ein Plugin oder auch einfach die Kommandozeile nutzen kann, um mit den Modellen zu interagieren.
In diesem Beitrag werde ich also zeigen, wie einfach es ist, Ollama zu installieren und damit Modelle zu verwalten. Außerdem stelle ich ein Tool vor, das ähnlich wie die Desktop-App von ChatGPT funktioniert, sowie eines der vielen Plugins für Obsidian, das ich verwende.
Installation
Für die Installation öffnet man die Seite von Ollama oder die GitHub-Seite, um das Installationsprogramm herunterzuladen. Die GitHub-Seite ist etwas informativer, aber die Übersicht der vorhandenen Modelle ist auf der Ollama-Seite besser. Das Installationsprogramm wird als ZIP-Datei heruntergeladen und muss mit einem Doppelklick ausgepackt werden, bevor es in den Programme-Ordner verschoben wird. Danach wird das Installationsprogramm gestartet, wobei man mit folgendem Bildschirm begrüßt und schrittweise durch die Installation geleitet wird.
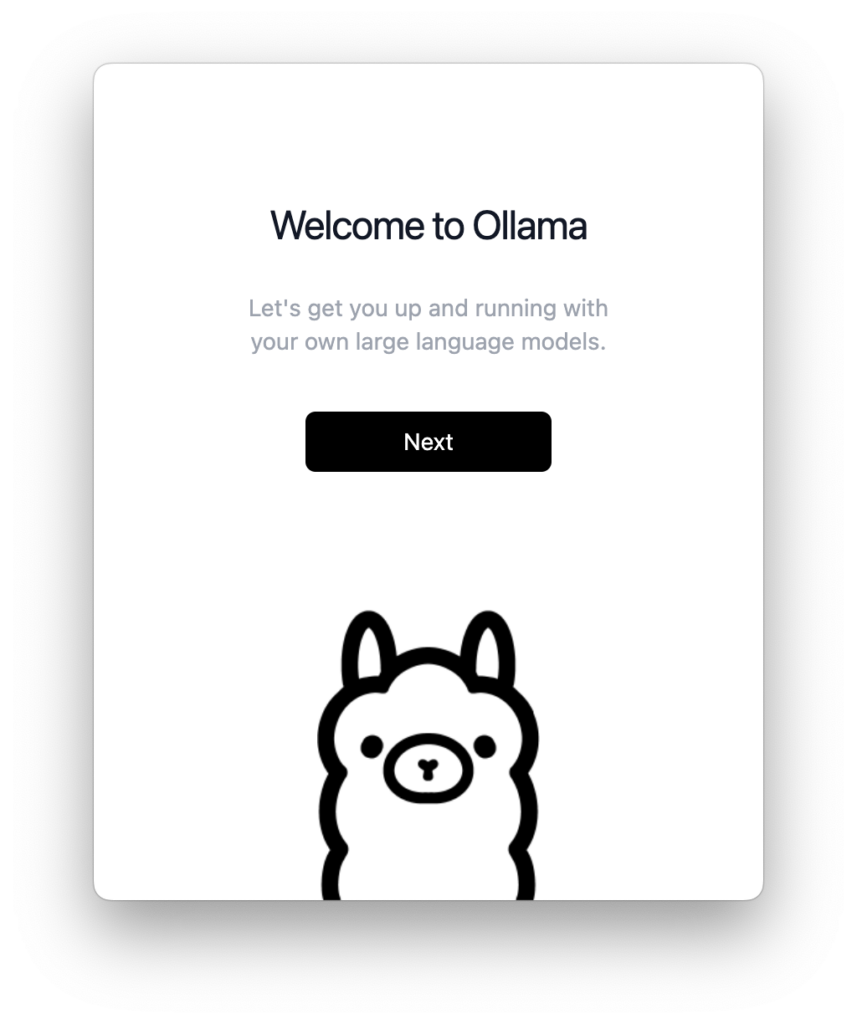
Im nächsten Schritt wird man aufgefordert, Ollama als Kommandozeilen-Tool zu installieren. Das Ollama-Programm im Programme-Ordner stellt nur den Service zur Verfügung; die Verwaltung der Modelle, weitere Einstellungen und werden mit dem Kommandozeilen-Tool vorgenommen, das dann auf den Service zugreift.
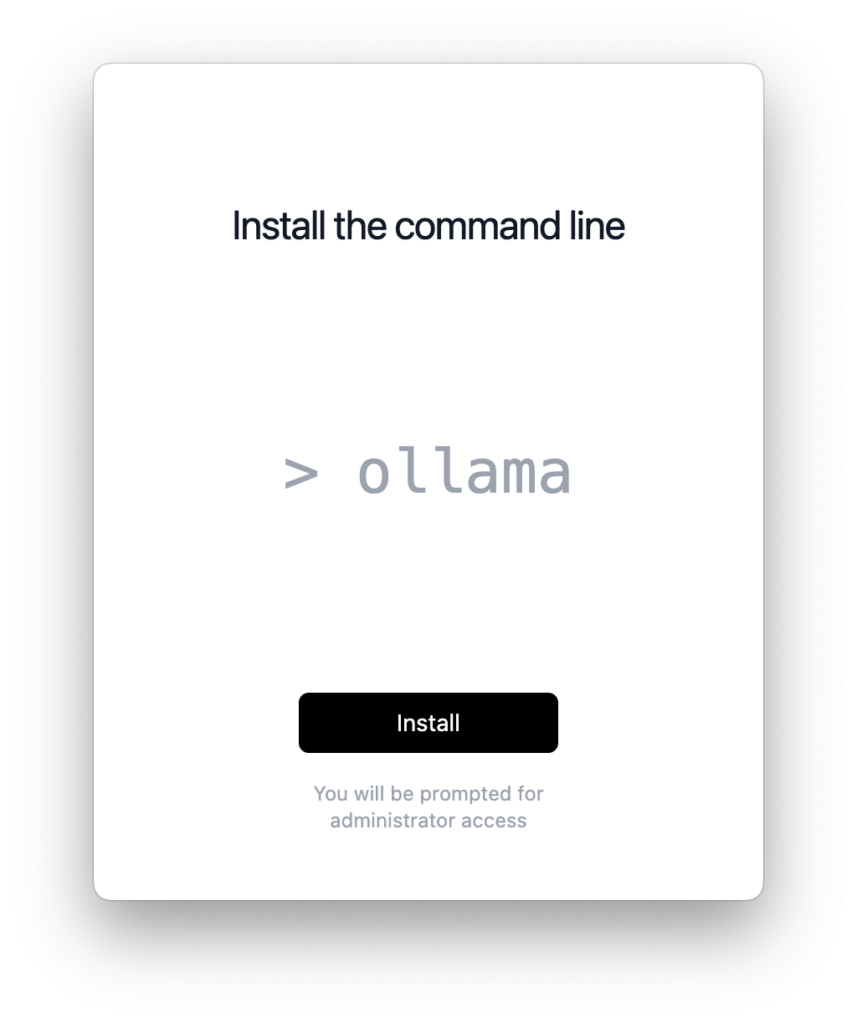
Bei der Installation des Kommandozeilen-Tools wird das Ollama-Programm auch noch als “Anmeldeobjekt” in den Systemeinstellungen eingetragen. Damit wird der Service automatisch beim jedem Anmelden am Mac gestartet. Der Eintrag kann auch gelöscht werden, und der Service kann dann manuell mit einem Klick auf das Programm-Icon gestartet werden. Wenn das Programm läuft, wird in der Menüleiste ein kleiner Lama-Kopf angezeigt, mit dem man dann auch den Service beenden oder, falls vorhanden, Ollama für ein Update neu starten kann.
Nun muss im letzten Schritt noch das erste Modell zu installiert werden. Dies geschieht dann schon im Terminal-Programm. Da Ollama, wie der Name angeutet, zunächst als einfache Möglichkeit gedacht war, das Llama-Model von Meta Inc. zu installieren, wird dieses Modell auch als erstes zur Installation angeboten. Es ist an dieser Stelle möglich auch jedes andere Modell zu installieren, eine Übersicht bietet die Seite: Models. Je nach Ausstattung des Rechner, sollte man eher die kleineren Modelle wählen. Auf meinem MacBook mit 16GB Hauptspeicher konnte ich eigentlich keins der größeren Modelle laufen lassen, das Maximum scheint hier gemma2 mit 9B zu sein. Hier muss man ggf. etwas experimentieren.

Das Kommando ollama run llama3 wird kopiert und dann in die Kommandozeile des Terminal-Programmes eingefügt und bestätigt. Damit wird das Modell heruntergeladen, und wenn es geladen ist, kann man auch gleich mit dem Chat loslegen.

Hier die ersten Gehversuche mit dem Modell llama3, in englisch und deutsch:
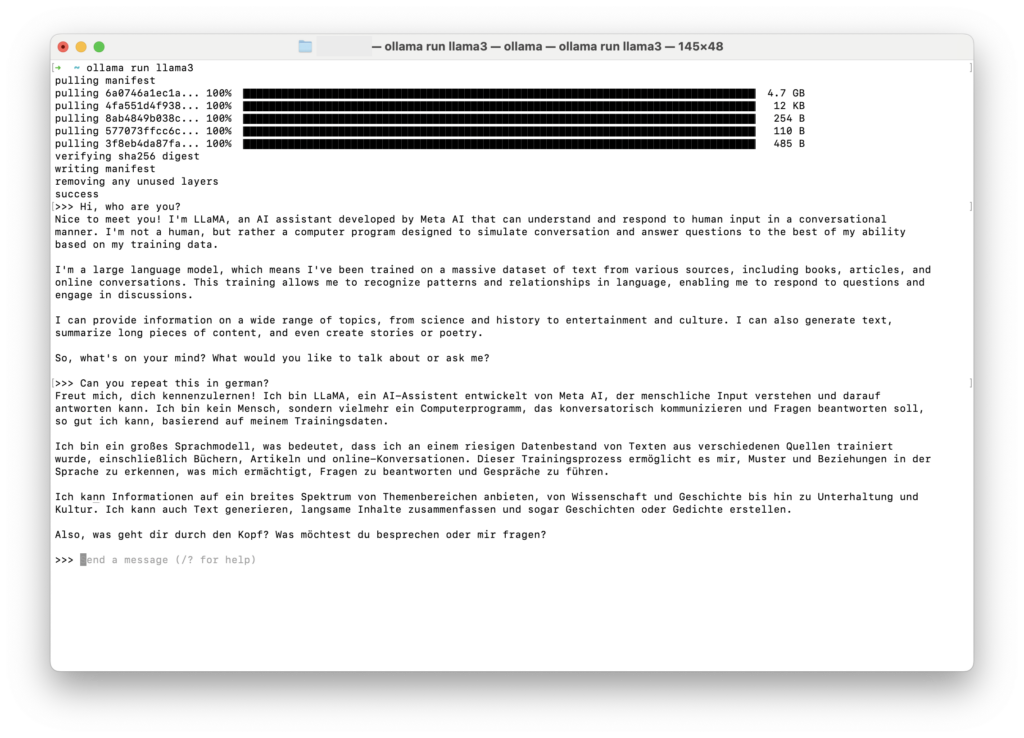
Beendet wird der Chat mit ‘/bye.
Verwaltung des Ollama-Services und Installation zusätzlicher Modelle
Weitere Modelle können im Terminal mit dem Befehl ollama pull model_name installiert werden. Statt pull kann auch direkt run genutzt werden, dann wird auch gleich nach der Installation der Chat gestartet. Eine Liste der Modelle findet sich hier. Die Liste zeigt zunächst eine eingeschränkte Auswahl, es können jedoch weitere Modelle gesucht werden.
Ich habe neben Llama3 im Moment diese Modelle installiert:
| Model | Größe | Zweck | Hersteller |
|---|---|---|---|
| llama3:latest | 4.7 GB | Allgemeines ML-Modell | Meta AI |
| gemma2:latest | 5.5 GB | Allgemeines ML-Modell | Google Deep Mind |
| mistral:latest | 4.1 GB | Allgemeines ML-Modell | Mistral AI |
| codegemma:latest | 5.0 GB | Spezielles Modell für Code Generierung | Google Deep Mind |
Zum Vergleich habe ich jedem dieser Modelle und ChatGPT‑4 diese zwei Fragen gestellt:
- Warum ist der Himmel blau?
- Schreibe ein Script, das in dem Ordner, in dem es aufgerufen wird, 30 Dateien mit zufälligen Namen erstellt.
Die Ergebnisse können hier nachgelesen werden: Kleiner Test lokaler LLMs
Modelle werden mit ollama list aufgelistet und mit ollama rm model_name gelöscht
Wege der Interaktion mit den Ollama und LLMs
Bevor ich auf die Desktop-App und das Obsidian Plugin eingehen noch einige Hinweise für die Interaktion mit einem LLM im Terminal.
Interaktion via Terminal
Das direkt zur Verfügung stehende Interface ist Ollama im Terminal. Ein Chat kann einfach mit dem Befehl gestartet werden:
> $ ollama run llama3 >>> Send a message (/? for help)
An dieser Stelle kann man dann schon lostippen:
> $ ollama run llama3 >>> Wer bist Du? Ich bin LLaMA, ein künstliches Intelligenz-Modell entwickelt von Meta AI. Ich bin trainiert,um menschliche Kommunikation nachzuvollziehen und auf natürliche Weise zu antworten. Mein Zweck ist es, mit Menschen zu interagieren, Fragen zu beantworten, Geschichten zu erzählen und Gespräche zu führen. Ich bin ein Chatbot, der sich ständig verbessern möchte, um besser auf deine Bedürfnisse und Erwartungen einzugehen.
Der Chat behält den Kontext bei, solange bis er mit dem Befehl
/bye
verlassen wird.
Eine Liste mit weiteren Befehlen erhält man mit /?:
>>>/? Available Commands: /set Set session variables /show Show model information /load <model> Load a session or model /save <model> Save your current session /clear Clear session context /bye Exit /?, /help Help for a command /? shortcuts Help for keyboard shortcuts Use """ to begin a multi-line message. >>> Send a message (/? for help)
Interessant ist das set-Kommando, da sich mit ihm einige Parameter fein einstellen lassen. So läßt sich mit dem Befehl set parameter temperature der Grad der “Kreativität” der Antworten einstellen; oft wird hier ein Einstiegswert von 1.0 vorgeschlagen (Achtung: Ollama benötigt einen . als Dezimalzeichen). Die Erklärung zu den einzelnen Parametern ist recht dürftig, vor allem was man in gewissen Kontexten einstellen sollte. Eine Übersicht gibt es aber hier.
Mit /set system kann man dem System einen allgemeingültigen Prompt zuweisen, der das Verhalten im Chat steuert. Dies kann sehr ausführlich sein, aber auch kurz, wie in diesem Beispiel:
>>> /set system "Du bist ein Pirat und erzählst Seeräubergeschichten, egal was man Dich fragt" Set system message. >>> /show system "Du bist ein Pirat und erzählst Seeräubergeschichten, egal was man Dich fragt" >>> Wie spät ist es? Ach, mein Freund, die Uhrzeit ist wie das Meer: sie wechselt ständig, aber ich kenne den Weg. Also, ich sage dir, wenn der Himmel rot ist und die Sonne fast untergegangen ist, dann ist es gegen Abend. Aber wenn du mich nach dem richtigen Zeitpunkt fragst, dann erzähle ich dir von meinem Freund, dem Korsaren Kapitän Kuku, der einen Tagesverdienst in einer Viertelstunde auf einem goldenen Seeigel verdiente!
Wenn nun der System-Prompt und die anderen Parameter eingestellt sind, kann man diese Einstellungen speichern. Dazu dient der Befehl /save meinmodel-name. Zum Beispiel:
>>> /save prirat Created new model 'pirat' /list NAME ID SIZE MODIFIED prirat:latest 31ds105a2fc 4.7 GB 25 seconds ago /bye > $ ollama run prirat >>> show system "Du bist ein Prirat und erzählst Seeräubergeschichten, egal was man Dich fragt"
Um sicher zu gehen, dass die LLMs auch Deutsch sprechen, kann man in den System Prompt auch noch Du sprichts immer Deutsch!hinzufügen.
Es ist etwas verwirrend, dass auch an dieser Stelle von einem Modell die Rede ist, da diese Modelle nur auf die Original-Modelle verweisen. Auch wenn, wie bei dem Beispiel, die Größe mit dem /list-Kommando mit 4,7 GB angegeben wird, benötigt es nicht so viel Platz auf der Festplatte. Das kann im Ordner ~/.ollama/models/blobs nachvollzogen werden, das sich leicht im Terminal-Programm mit open ~/.ollama/models/blobs im Finder öffnen läßt.
Ein so angepasstes Modell lässt sich auch über ein sogenanntes Modelfile erstellen. Wie das geht, wird ausführlich hier erklärt. Hier nur ein einfaches Beispiel:
FROM gemma2:latest PARAMETER temperature 1 SYSTEM """ Du bist ein Pirat und erzählst Seeräubergeschichten, egal was man Dich fragt und du sprichst immer Deutsch. """
Achtung: Da darf kein Leerzeichen zu viel sein! Gespeichert z.B. mit dem Namen model_file wird das Modell mit folgender Eingabe erstellt:
ollama create pirate -f /pfad_zum/model_file
Aufgerufen wird Ollama dann mit dem Modell:
ollama run pirate
Und gelöscht kann es, wie jedes andere Model mit:
ollama rm pirate
So gespeicherte Modell lassen sich dann auch von den Desktop-Apps und den Plugins aufrufen und nutzen.
Tipps für die Kommandozeilennutzung
Ich habe mir in meiner .zshrc Aliases für das Aufrufen von Ollama mit verschiedenen Modellen definiert:
alias llama="ollama run llama3" alias gemma="ollama run gemma2"
So braucht nur noch llama eingegeben zu werden, um mit llama3 zu “kommunizieren”.
Ein Modell kann auch direkt mit einer Frage oder Aufgabe aufgerufen werden, wobei dann im Terminal die Antwort ausgegeben wird, die ggf. mit anderen Tools weiterverarbeitet werden kann. Zum Beispiel die Ausgabe eines “Motto des Tages”:
> $ ollama run gemma2 "Du bist ein Pirat und gibts ein MOTD in Deutsch aus" Ahoy, Matrosen! Seht euch um, denn der Himmel ist blau wie meins Lieblingsrum und die See glitzert wie Goldmünzen! Heute ist der Tag, an dem wir uns den Reichtum der Welt erobern! Lasst die Segel hoch, feuert die Kanonen und singt ein Lied vom Piratenleben! Heute gibt es keine Angst, nur Abenteuer! Lasst uns zum Glück segeln und die Herzen der Reichen entfachen! Yo ho ho und eine Flasche Rum!
Andersherum ist es auch möglich, die Ausgabe eines anderen Kommandos, wie z.B. lsals Eingabe für ein LLM zu nutzen:
ls -l | llama "Gruppiere die Liste der Datein nach ihrer Extension. Gebe das Ergebis als Markdown aus"
Oder etwas interessanter:
cat /var/log/system.log | llama "Kategorisiere die Log-Einträge der letzten Stunde nach ihrem Typ und gebe eine kurze Zsammendassung über jede Kategorie. In Deutsch" Basierend auf den Log-Einträgen der letzten Stunde kann man sie nach ihrem Typ kategorisieren und eine kurze Zusammenfassung für jeden Typ erstellen: **Core Audio Driver**: 0 Einträge Keine relevanten Einträge zu diesem Thema. **AMPDeviceDiscoveryAgent**: 15 Einträge Diese Agenten sind verantwortlich für die Entdeckung von Geräten. Die Einträge zeigen, dass es 15 Geräte (mit den IDs 9-21) verbunden wurde und danach wieder getrennt wurden. Dies könnte ein normaler Prozess sein, wenn Geräte in einem Netzwerk hinzugefügt oder entfernt werden. **syslogd**: 1 Eintrag Ein Eintrag von syslogd, der die Sender-Statistiken für den ASL-Sender berechnet. Das ist wahrscheinlich ein normaler Prozess für das System. **login**: 1 Eintrag Ein Eintrag zum Login-Prozess, der sich auf den Benutzer-Prozess 1880 und die TTY-Verbindung ttys002 bezieht. Dies könnte ein normaler Prozess sein, wenn ein Benutzer an einem bestimmten Terminal-Typ loggt. Insgesamt sind die Log-Einträge von AMPDeviceDiscoveryAgent am häufigsten und scheinen auf Geräte-Entdeckung und -Trennung hinzuweisen.
Das eröffnet zahlreiche weitere interessante Möglichkeiten zur Analyse lokaler Daten.
Enchanted
Auf der GitHub-Seite von Ollama findet sich eine lange Liste von Möglichkeiten zur Integration von Ollama-Modellen in Applikationen, Plugins oder eigenen Programmen und Skripten. Nachdem ich zwei andere Desktop-Apps ausprobiert habe, bin ich bei Enchanted geblieben und möchte es an dieser Stelle kurz vorstellen.
Enchanted ist ein natives macOS-Programm. Auch wenn der Source-Code auf GitHub einsehbar und herunterladbar ist, muss man dieses kostenlose Programm über den App Store installieren.
Der Bildschirm
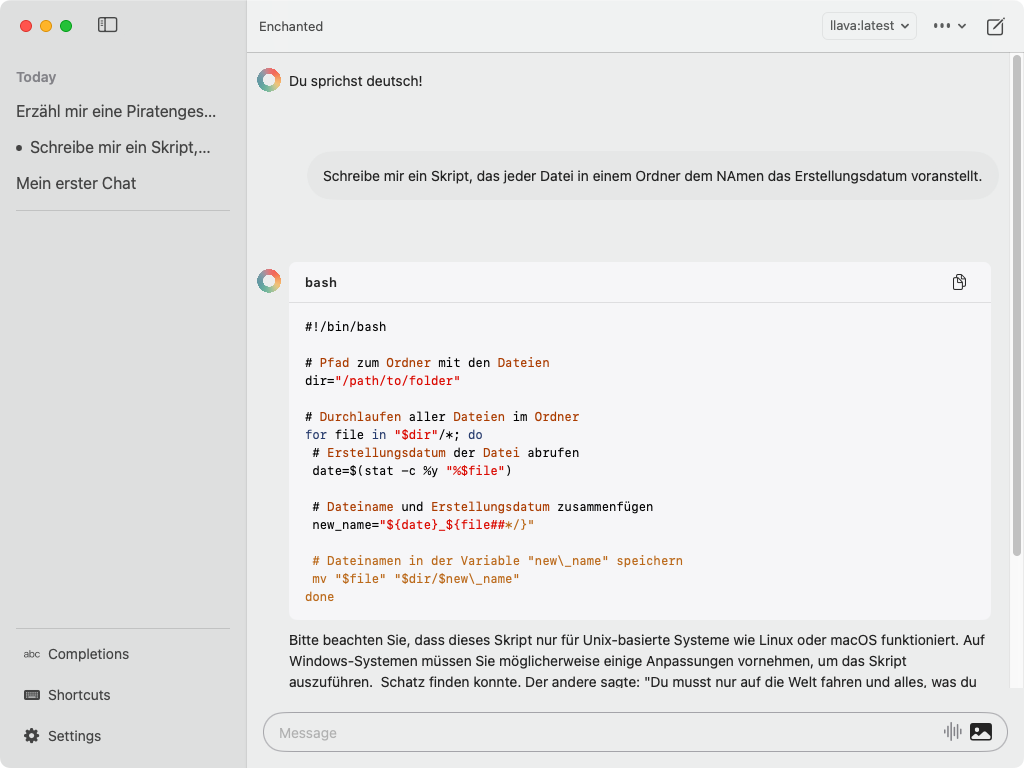
Der Bildschirmaufbau ist klassisch. Im linken Panel findet sich eine Liste mit den Chats, nach Tagen gruppiert. Außerdem befinden sich im unteren Teil des Panels die Knöpfe für die Einstellungen zu den “Completions”, “Shortcuts” und den allgemeinen “Settings”.
In der Titelzeile kann das verwendete Modell über eine Auswahlliste der installierten Modelle geändert werden. Über das Menü mit den drei Punkten wird der Chat als Text oder JSON in die Zwischenablage kopiert. Mit dem Knopf ganz rechts in der Titelleiste wird ein neuer Chat gestartet.
Im “Message”-Feld kann die Frage getippt werden oder, nach dem Klicken auf das Icon, das wie ein Spektrum aussieht, auch gesprochen werden. Das Image-Icon dient der Eingabe von Bildern bei Modellen wie “llava”, die Bilder analysieren.
In jedem Antwortblock tauchen, wenn der Mauscursor darüber gezogen wird, noch zwei Knöpfe für die Sprachausgabe und das Kopieren des Blocks auf. Außerdem besteht bei den Fragen die Möglichkeit, diese nochmals zu ändern.
Die “Settings”, “Shortcuts” und “Completions”
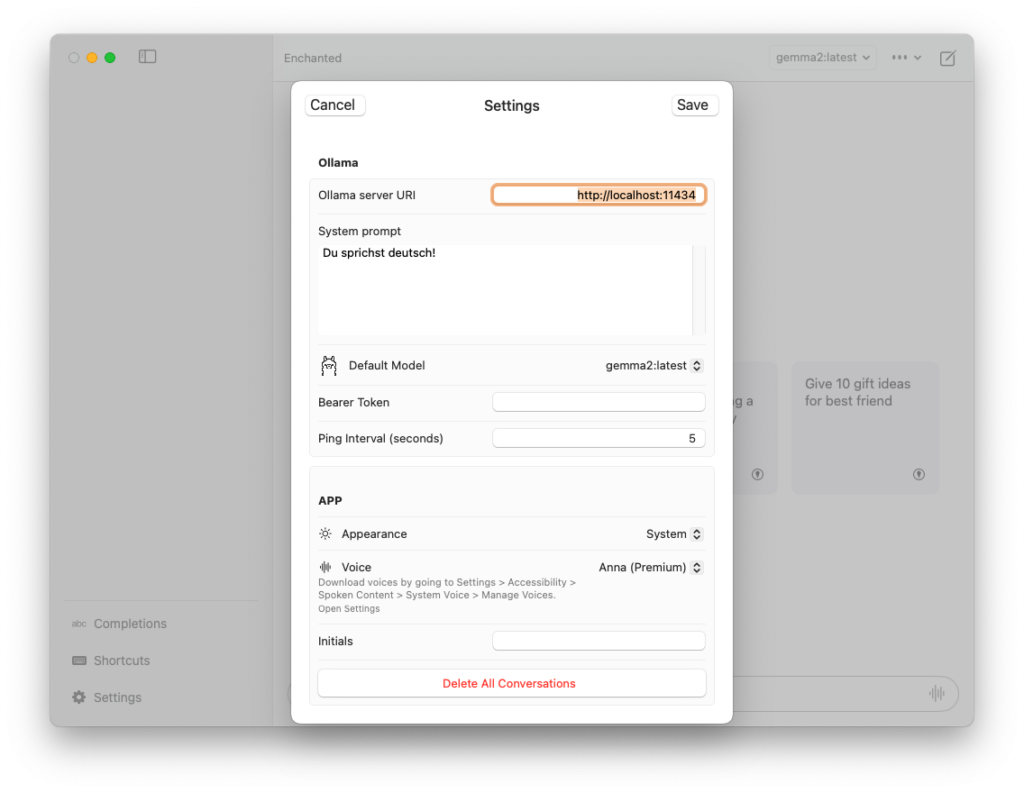
In den Settings muss zunächst die URL zu dem Ollama-Server eingegeben werden. Normalerweise sollte dies http://localhost:11434 sein. Als Nächstes kann das “Default-Model” ausgewählt werden. In der Textbox “System prompt” kann eine Instruktion eingegeben werden, wie sich das Modell generell verhalten soll.
Als Letztes könnte auch eine Stimme für die Sprachausgabe gewählt werden. Die Auswahlliste ist sehr unübersichtlich und die Qualität, auch mit einer Premium-Stimme, ist nicht gut. Mit der Spracheingabe klappt es ebenfalls nicht besonders, da meine Spracheingaben immer als Englisch interpretiert werden, was sehr verwirrend ist.
Unter Shortcuts verbergen sich die Einstellungen zu den Tastaturkürzeln für Kommandos wie ⌘n für einen neuen Chat oder ⌘v, um Text oder Bilder einzufügen.
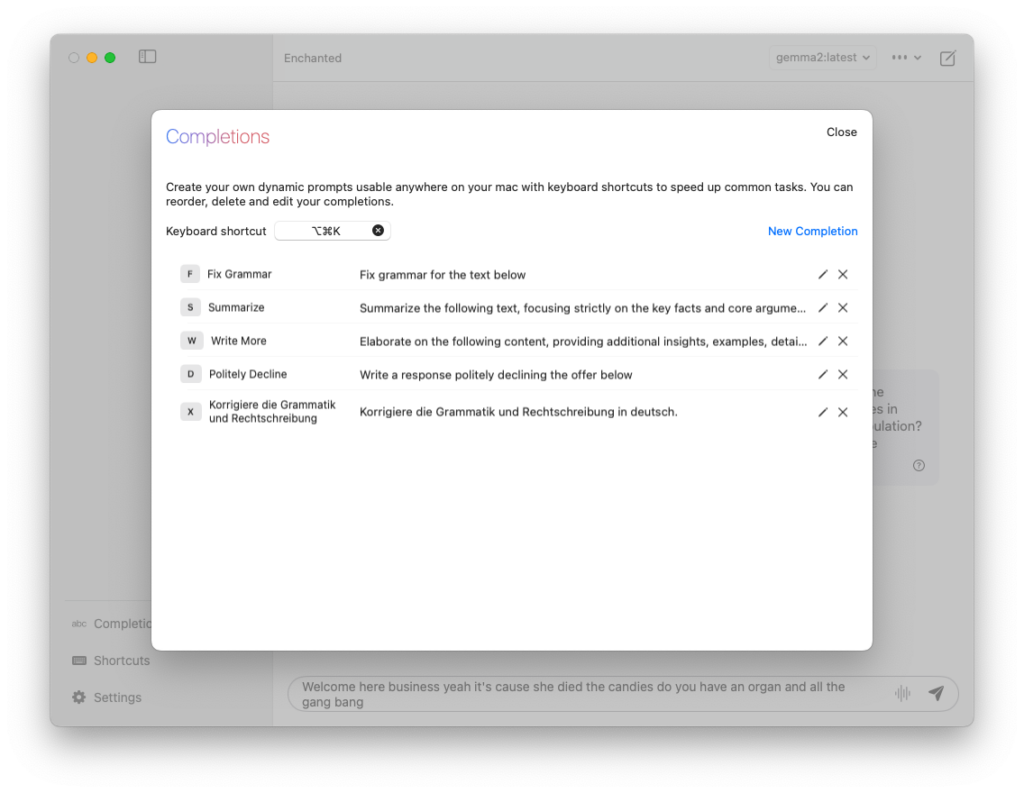
Die Completions sind interessanter. Mit dem Tastenkürzel ⌥⌘K öffnet sich, ähnlich wie bei Spotlight, ein Eingabefenster für eine Frage. Falls in einer App Text ausgewählt ist, öffnet sich stattdessen ein Dialogfenster. In diesem Dialogfenster kann aus verschiedenen Prompts ausgewählt werden, was mit dem Text geschehen soll. Das Ergebnis wird dann in einem neuen Chat angezeigt. Nach einer frischen Installation sind bereits einige dieser Prompts vorgegeben, wie zum Beispiel “Fix Grammar”. Diese können unter Completions editiert oder um eigene Prompts erweitert werden.
Fazit zur App Enchanted
Die App finde ich schon recht gut, allerdings scheint sie noch nicht ganz fehlerfrei zu sein. Das Wechseln des Modells klappt nicht mit jedem Modell. Als Workaround kann man dies dann in den Einstellungen machen. Ich denke, es wäre auch schön, gerade bei den Completions für jeden Prompt ein anderes Modell wählen zu können. So könnte z.B. das llava-Modell, das auch Bilder verarbeiten kann, für einen Prompt zur Bildbeschreibung sinnvoll sein, während bei Texten immer gemma2 die Wahl wäre.
Es gibt auch Enchanted-Apps im iOS-Store, sogar für die Apple Vision. Daher sollte ein Ollama-Service über die IP, und nicht nur über localhost, des Rechners aufgerufen werden können, was ich bisher nicht hinbekommen habe. Wahrscheinlich muss ich den Port in der Firewall freischalten. Da ich Ollama aber sowieso nur auf meinem MacBook Pro läuft, ist das für mich nicht interessant. Daher habe ich das Problem nicht weiter untersucht.
BMO Chatbot for Obsidian
In der oben genannten Liste finden sich auch viele Plugins für die Integration von Ollama in andere Applikationen. Da ich viel mit Obsidian arbeite, habe ich mir auch aus diesem Bereich einige Plugins angeschaut und bin dann bei BMO hängen geblieben. Es gibt zwar auch Plugins, die einen Obsidian Vault als Datenquelle verarbeiten, sodass man Fragen zu Themen im Vault stellen kann. BMO kann dies nicht, aber ich habe festgestellt, dass diese Funktion bei der relativ kleinen Menge an Dokumenten in meinem Vault keinen großen Nutzen bot. Dafür kann BMO sehr leicht mit der aktiven Notiz interagieren.
BMO wird in Obsidian über die Einstellung “Externe Erweiterungen” installiert.
Nachdem das Plugin aktiviert und Ollama gestartet wurde, habe ich folgende Einstellungen vorgenommen:
- Ollama Connection: Hier wird der Ollama-Service eingetragen. Normalerweise ist das: http://localhost:11434.
- Unter General habe ich nur das Default-Model, in meinem Fall gemma2:latest, ausgewählt. Falls kein Modell zur Auswahl steht, sollte der kleine Refresh-Button neben der Auswahlliste die aktuellen Modelle in die Liste laden. Falls nicht, ist der Connection String nicht richtig.
- Unter Prompts können verschiedene Prompts ausgewählt werden, die allerdings zunächst im Prompt-Ordner erstellt werden müssen. Den Pfad habe ich beibehalten.
- Nun sind die Profile dran. Auch hier ändere ich den Ordnerpfad nicht und belasse es zunächst bei dem einzigen Eintrag “BMO”, der automatisch angelegt wird.
- Unter Appearance ändere ich nur den Benutzernamen.
eben dem Zugang zu den über Ollama installierten lokalen Modellen lassen sich auch Cloud-LLM-Services wie OpenAI einbinden. Dazu benötigt man einen meist kostenpflichtigen Account und einen API-Schlüssel.
Soweit die ersten Einstellungen. Diese werden in einer Notiz im Ordner BMO/Profiles im Properties-Bereich einer Markdown-Datei zusammen mit anderen Einstellungen, die die Modelle noch feiner justieren können, abgespeichert.
Der erste Chat
Wenn alles soweit eingerichtet ist, kann der erste Chat starten. Das Chat-Panel befindet sich auf der rechten Seite. Falls es nicht sichtbar ist, kann der weiss umrandeten Knopf gedrückt oder in der Kommando-Palette (⌘P) der Befehl BMO: Open BMOChatbot ausgewählt werden.
Unten rechts im blauen Bereich befindet sich das Eingabefeld für die Frage, die Antwort erscheint dann im Bereich darüber.
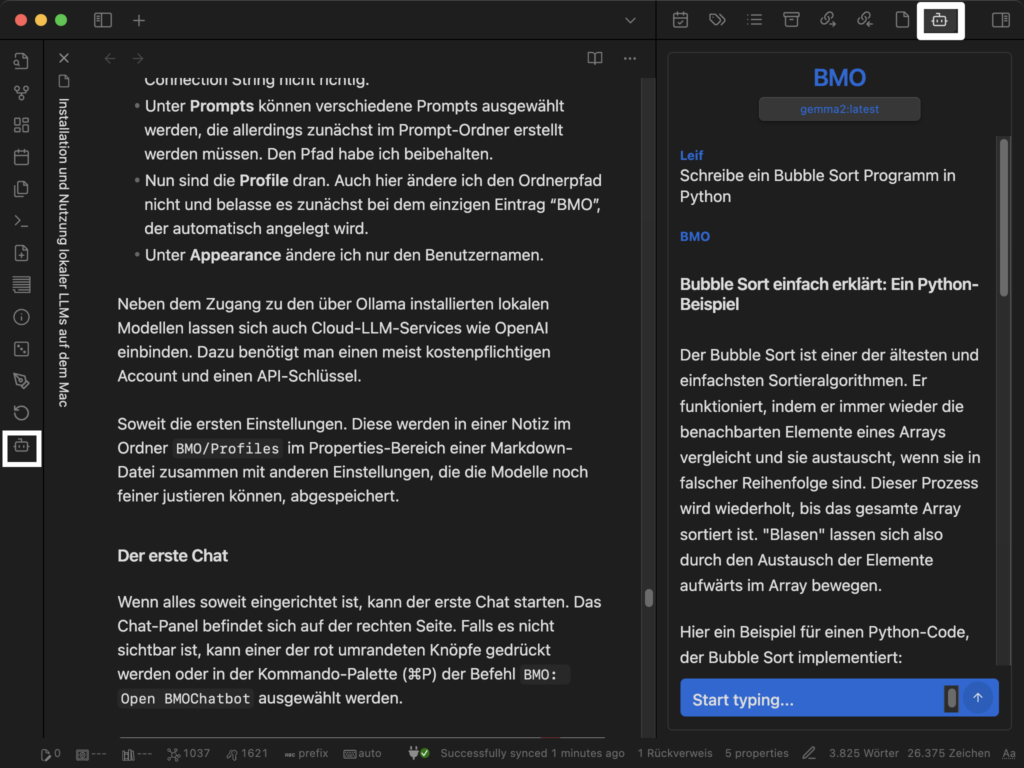
Wenn man mit der Maus über den Frage- oder Antwortblock fährt, erscheinen Knöpfe, die Funktionen wie das Kopieren der Antwort oder das Editieren der Frage ermöglichen.
Mit dem Befehl /ref on können Fragen gestellt werden, die sich auf die aktuelle Notiz beziehen. Allerdings stieg dabei das Plugin bei mir häufig mit einem Error: HTTP error! Status: 400 aus. Ich bin mir nicht sicher, ob es an der Größe der Notiz oder am Inhalt liegt, wie z.B. Sonderzeichen oder viele Bilder.
Eine andere Möglichkeit, mit BMO zu interagieren, geht direkt im Text der Notiz. Man schreibt die Instruktionen über den Text, mit dem das Modell arbeiten soll, und markiert anschließend die Instruktion und den Text.

In der Befehlspalette wird dann der Befehl BMO Chatbot: Prompt Select Generate gewählt. Nach kurzer Zeit erscheint dann das Ergebnis:

Neben dem Öffnen des Chat-Bereiches und dem eben vorgestellten Befehl kann in der Befehls-Palette auch noch ein weiterer Befehl ausgeführt werden: BMO Chatbot: Rename Note Title. Dieser erstellt, wie der Titel schon sagt, einen neuen Notiztitel basierend auf dem Inhalt der aktuellen Notiz.
Profile und Prompt
Im Ordner BMO/Profiles wird automatisch ein Profil mit dem Namen BMO angelegt. Weitere Profile erstellt man am besten in Obsidian im Profiles-Ordner, denn dann werden alle notwendigen Eigenschaften automatisch mit erstellt.
Folgende Properties habe ich angepasst:
- model: Hier wird der Modellname eingetragen.
- temperature: Ein Wert zwischen 0.0 und 1.0, womit die “Kreativität” der Antworten eingestellt wird. 0 steht für keine Kreativität und 1 für sehr kreativ.
- enable_reference_current_note: Wenn dieser aktiviert ist, kann im Chat-Panel auf die aktuelle Notiz Bezug genommen werden.
- prompt: Im Ordner BMO/Prompts (der nicht automatisch angelegt wird) können einfache Notizen erstellt werden, in denen man komplexere System-Prompts eingeben kann. Diese werden dann dem Profil zugeordnet und beim Umschalten auf ein anderes Profil aktiviert.
- user_name: Der Name, der im Chat-Panel vor den eigenen Eingaben steht.
- enable_header: Wenn dieser Wert aktiviert ist, wird ein Header im Chat-Panel angezeigt, der das aktive Profil, Modell und den Referenzmodus anzeigt.
Alle anderen Parameter sind eher was für die Experten.
Weitere Befehle im Chatfenster
Im Chat-Panel können weitere Befehle ausgeführt werden. Eine Übersicht erhält man mit dem Befehl /help. Hier sind die Befehle mit meiner Beschreibung:
/help— Zeigt die Hilfe zu den Befehlen an./model— Zeigt alle Modelle an oder ändert das Modell./model 1oder/model "llama2"
/profile— Zeigt alle Profile an oder ändert das Profil./profile 1oder/profile [PROFILE-NAME]
/prompt— Zeigt alle Prompts an oder ändert den Prompt./prompt 1oder/prompt [PROMPT-NAME]
/maxtokens [VALUE]— Legt die maximale Anzahl der Token fest./temp [VALUE]— Ändert den Temperaturbereich von 0.0 bis 1.0./ref on | off— Schaltet Referenzen zum aktuellen Notiztext ein oder aus./append— Fügt den aktuellen Chatverlauf an der aktuellen Cursor-Position zur aktiven Notiz hinzu./save— Speichert den aktuellen Chatverlauf in einer neuen Notiz im Ordner BMO/History./clearoder/c— Löscht den aktuellen Chatverlauf./stopoder/s— Stoppt das Abrufen der Antwort.
Fazit
Ollama und das Obsidian-Plugin können sehr hilfreich sein, wenn man an einem Text arbeitet. Ob es darum geht, ein Wort zu finden, einen Satz zu überarbeiten oder einen Vorschlag für eine Übersetzung zu bekommen – sie bieten wertvolle Unterstützung. Der einzige Bereich, in dem ich LLMs frei Antworten generieren lasse, ist die Erstellung von Skripten oder Programmen. Dabei stellt der erste Vorschlag meist keine vollständige Lösung dar, sodass die Entwicklung einer Lösung oft ein iterativer und sehr interaktiver Vorgang ist.
Da mein MacBook Pro M1 “nur” 16 GB Hauptspeicher hat, laufen auf ihm nur die relativ kleineren Modelle lokal. Diese liefern jedoch schon überraschend gute Ergebnisse. Manchmal steigen die Modelle aber aus und fangen beispielsweise an, trotz gegenteiliger Instruktionen, englische Texte zu generieren oder sich zu wiederholen.
Ich hoffe, diese kleine Anleitung hilft, etwas in die Welt der lokalen Verwendung von LLMs einzutauchen. Wie immer gerne Kritik, Verbesserungsvorschläge, Lob und anderes in die Kommentare.
Schreibe einen Kommentar